No doubt if you are in academia right now–or even outside of academia you might’ve heard a bit about digital humanities. While researching end-of-semester papers, I thought I would test out a few DH tools for research that have been recommended to me and see how well they work for my subject matter. I’ll be testing JSTOR’s Text Analyzer and Connected Papers.
The Research Paper (in brief)
Project: Sutra Transcription in Medieval Japan
Time Period: 700-1200 ish
Place: Japan
Keywords: “sutra” “transcription” “text” “setsuwa”
Summary: In Buddhism, sutras are scriptures said to be a record of the Buddha’s teachings. Over the course of the development of Buddhism, particularly in East Asia, copying sutras was very popular as a merit-making practice. I am looking at the history of sutra transcription practices in Japan.
I’ve gathered quite a few resources so far the “old-fashioned” way. I started by searching the catalog for books on the subject and looking at their bibliographies to get more sources. Thus far my most “high tech” moment has been using the online catalog. But I’m going to try to plunge into the world of DH tools to try to find some more resources/round out my bibliography.
Jstor’s Text Analyzer is a relatively new tool from Jstor, a database of journal articles, books, and primary sources. In the past, I’ve mainly used it for scholarly articles and book reviews for the humanities. Here is the description of the Text Analyzer from their website.
Jstor’s Text Analyzer
“Text Analyzer is a beta tool built by JSTOR Labs. With it, researchers can search for content on JSTOR just by uploading a document.”
See their description and video at https://www.jstor.org/analyze/about
So the idea is that you upload or paste in a document and the Analyzer reads it, identifies the key themes, and then looks for other sources based on the document you uploaded. Sounds useful to me!
The article I am using is,
Eubanks, Charlotte. “Illustrating the Mind: ‘Faulty Memory’ Setsuwa and the Decorative Sutras of Late Classical and Early Medieval Japan.” Japanese Journal of Religious Studies 36, no. 2 (2009): 209–30. http://www.jstor.org/stable/40660966.
I chose this article because it’s on Jstor, the journal (JJRS) is a major one in my field and I know the whole back catalog is on Jstor, and it has most of my keywords in the title. I’ve already read it and I know it’ll be useful to my paper so it seemed like a good place to start. I tried another one at first–but I think the analyzer is limited to articles on jstor/articles that are OCR-able.
Trial 1: Error Message…
Trail 2: Did the same thing, but expected different results.
Success!
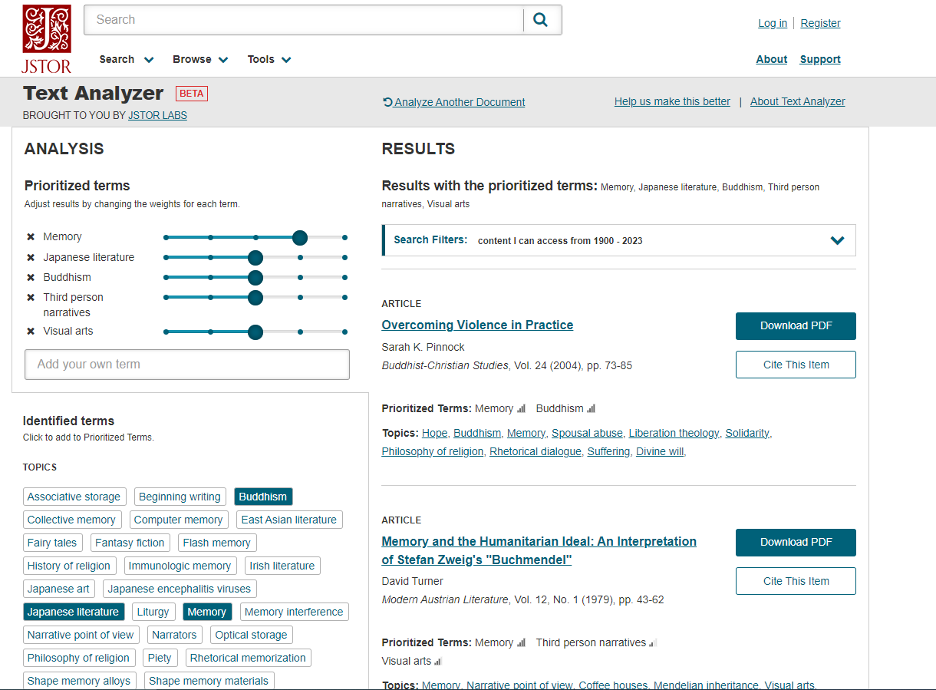
Text Analyzer identifies “topics” and highlights what it’s identified as “prioritized terms” and assigns them a “weight” based on how it reads the text. You can then change which words you think should be prioritized and how much weight it should put on each term for different results.
The prioritized terms identified were “memory, Japanese literature, Buddhism, third person narratives, and visual arts” all of which are subjects in the paper.
As for the recommendations…they’re a little less than stellar. The first 10 results included the prioritized terms however it doesn’t seem like they are looking at the same kind of primary sources as the article I submitted. Some are in different time periods or look at unrelated subjects as their primary thesis.
*Number of sources I would read for far 0/10.*
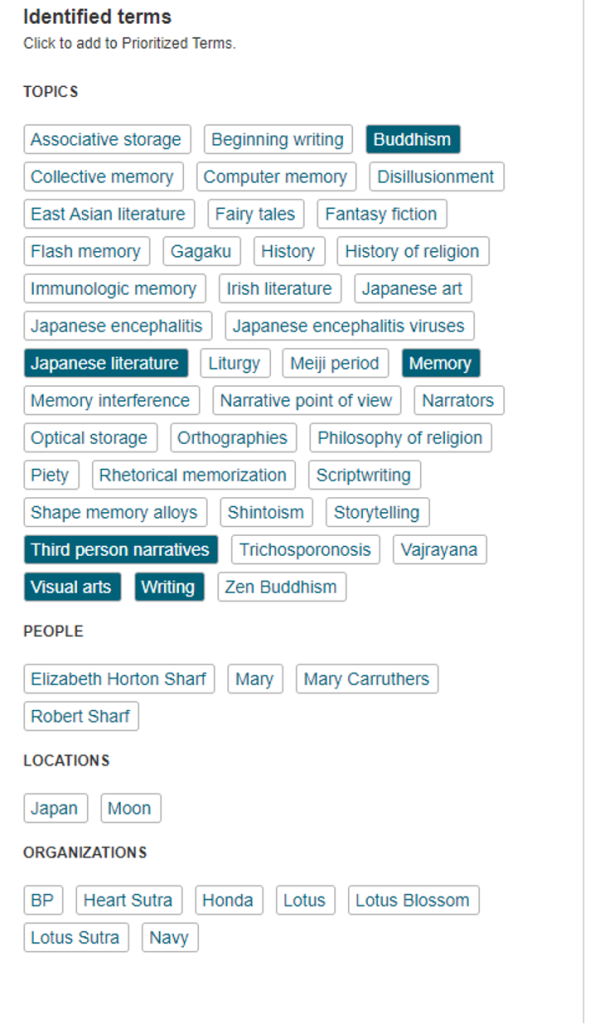
Adjusting the weight. Next, I tried to adjust the terms and the weight of the terms to see if I could get better results. It also identifies people, places, and organizations that you can click on to prioritize. Also apparently the main locations in my text are Japan and the Moon.
The adjustment yielded better results. The first result is a chapter from a book I’ve already read for the project and is by the same author as the article jstor is analyzing from.
There are also two articles I think could be useful
Schneider, Mark. “THE DIFFERENCE ENGINE: MANUSCRIPTS, MEDIA CHANGE AND TRANSMISSION OF KNOWLEDGE IN PREMODERN JAPAN.” Rivista Degli Studi Orientali 84, no. 1/4 (2011): 67–83. http://www.jstor.org/stable/43927258.
Robson, James. “Signs of Power: Talismanic Writing in Chinese Buddhism.” History of Religions, vol. 48, no. 2, 2008, pp. 130–69. JSTOR, https://doi.org/10.1086/596569. Accessed 3 Nov. 2023.
Useful 2.5/10 (the .5 is for the chapter I already read)
(you can also toggle between showing “content from jstor” vs “all content.” You can select whether you want jstor to show you only content it has access to vs all the content it knows about. I didn’t find a difference when I used it.)
Final Thoughts on Jstor’s Text Analyzer:
It seems like a promising feature. The interface is intuitive and easy to navigate. It does a good job of reading and giving terms related to the topic. My main issue is that I didn’t find its results to be particularly helpful to me. Compared to what I find by tracing bibliographies and looking for books on the shelf, I don’t think this tool would give me a very thorough bibliography of the major works in the field. It could be that it’s a very specific subject or maybe if I put in a different paper I’d get better results.
It’s also still in beta so I’ll try again once they’ve made more tweaks–I’m cautiously optimistic and might return for a different paper.
Connected Papers
Connected Papers looks really cool at first sight. The way it works is that you input an article and Connected Papers creates a visual network based on that paper, in theory, you can use it to understand trends in the field, get an overview of major important works, and understand the dynamics of the field. Sounds awesome!
So I tried inputting the same paper I used for Jstor to see how the results varied.

The graph looks super cool. The origin paper is listed on the right and in the top left. On the left, there is a list of related papers and the graph shows a visualization of how all the papers are connected. You can toggle between lists of prior works and derivative works as well as filter by keyword, publication date, and pdf available/open access sources. You can also download it. I found that by opening it in Adobe Illustrator and Firefox you get a text file of the first five articles.
While I can see how the papers it procured are related to my topic, I don’t think any of them are what I am looking for. The ones relating to yokai, the konjaku monogatari, and Buddhist relics are relevant to the paper I put in, but they don’t relate to sutra transcription.
Connected Papers identified 10 prior works as “important seminal works” in the field.
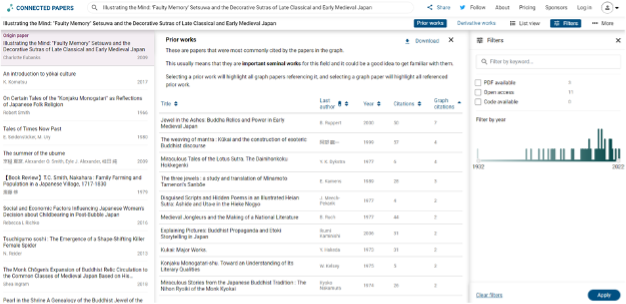
I’ve read 5 of them and the others I’ve either heard of or am familiar with the author–so I think Connected Papers did a really good job of identifying major works.
Relevant papers: 8/10 (works I’ve read and/or have seen in my research)
Connected Papers also identifies derivative works, papers that “cited many of the papers in the graph” and are “either surveys of the field or recent relevant works.”
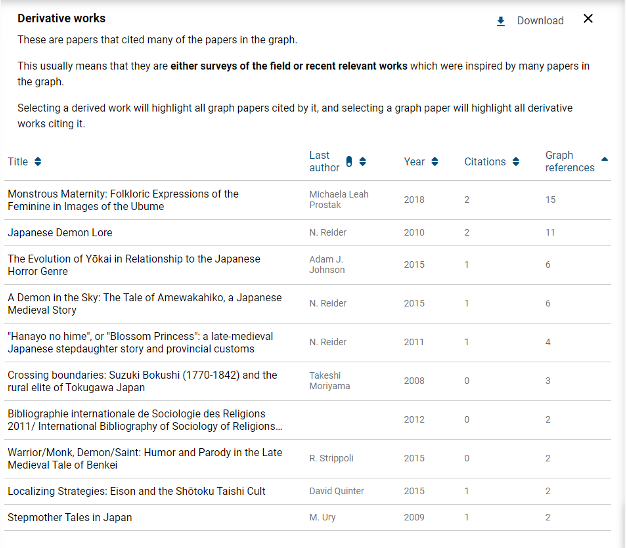
While I can understand how it sourced the derivative works and could see them being relevant to a different paper, I won’t be using any of them because they are largely unrelated to sutra transcription practices.
Relevant derivative works: 0/10
Final Thoughts on Connected Papers:
I think it’s a cool concept and I could see how it could be useful to someone exploring a topic. The limited number of free graphs is an obstacle to consider in using it. I think that for me it was not the most useful but that could be partially because of the stage I am at in my work.
Connected Papers limitations:
2 free per month
5 free per month w/ registration
After that paid service
Final Thoughts:
I like the idea of these digital humanities tools and I could see them being useful for someone first starting a project. However, I might’ve been at the wrong stage in my research to make the best use of these tools. I won’t be using them any further for this project because I haven’t gotten much new information and because I feel as though my current methods work reliably well and adding something new would take more time than it’s worth. This being said, I encourage everyone to at least try the tools! They might work better for some projects than others.